Imagebucket
How to use Imagebucket:
Upload:
Hit the "Upload" button to add multiple images from your device.
Crop:
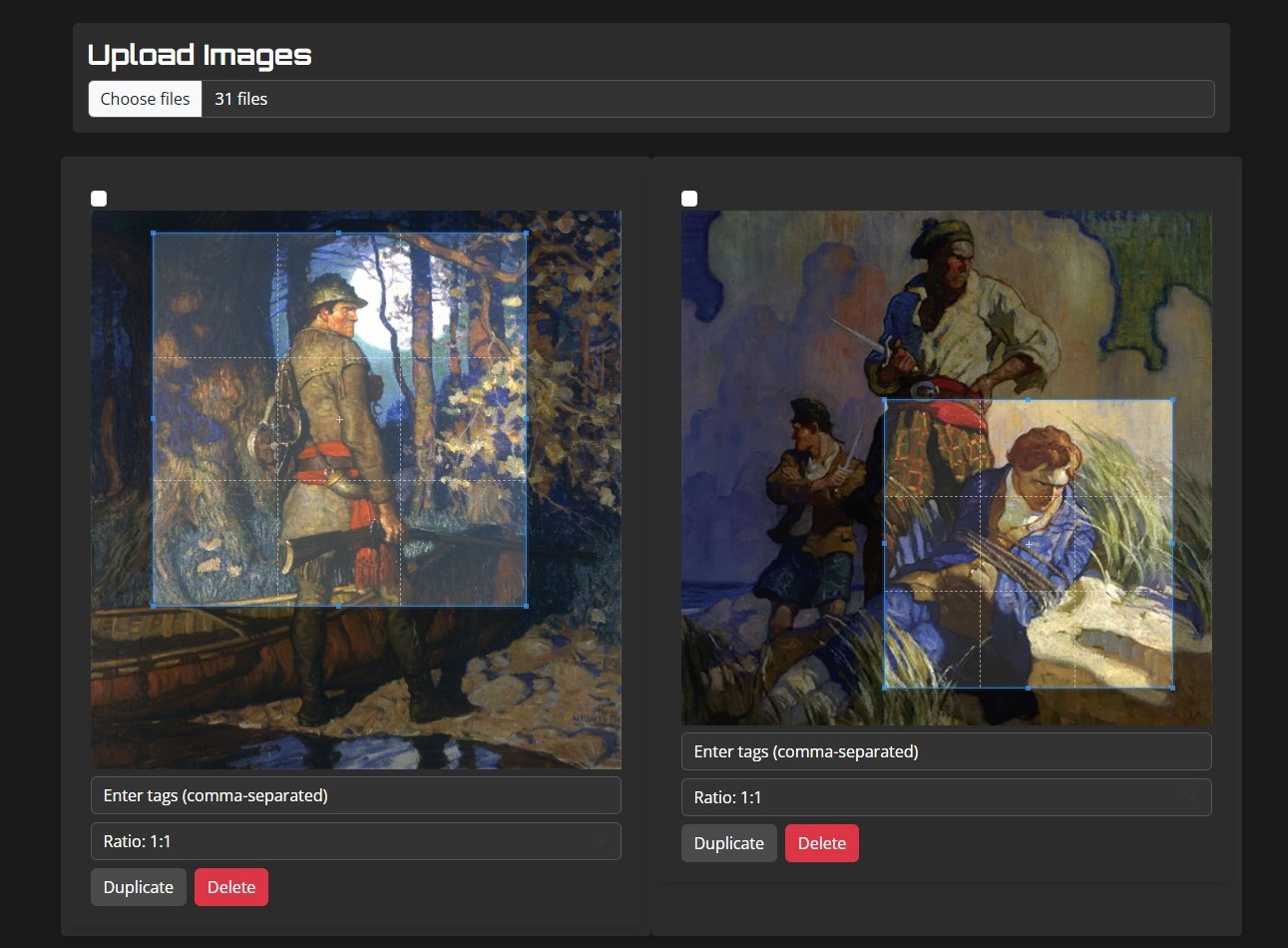
Once your images are uploaded, use the cropper tool to select and frame the specific area of each image you want the model to focus on. This helps highlight the most relevant parts of your images for training.
Aspect Ratio and Bucketing:
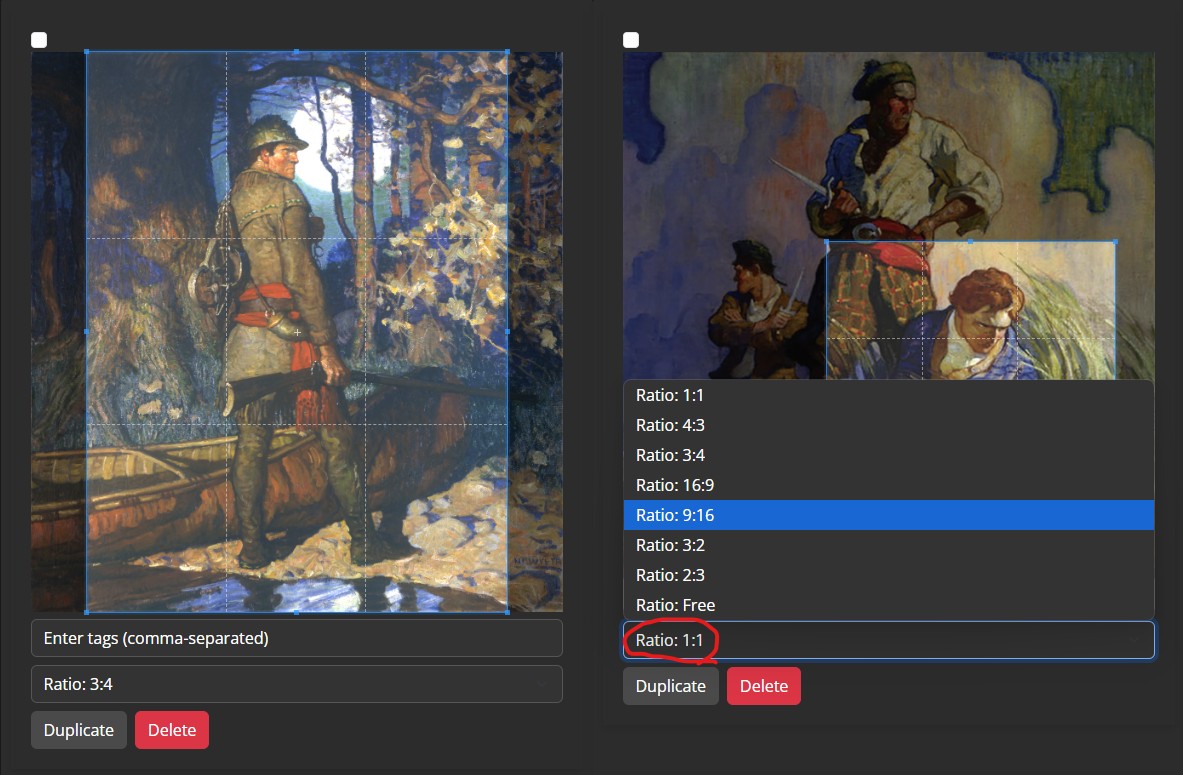
By default, Bucket feature is on by default in platforms like Kohya_SS and Civitai’s online training. This feature will allow training for images that are in different aspect ratios and resolution. Imagebucket allows users to pick different aspect ratios for each individual image.
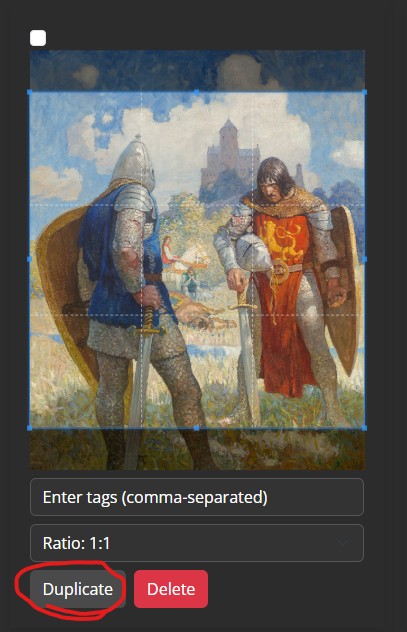
Duplicating Images:
The image management tool includes a "Duplicate" button, allowing you to quickly create copies of your existing images to expand your dataset. This is especially helpful if you’re working with a limited number of unique images.
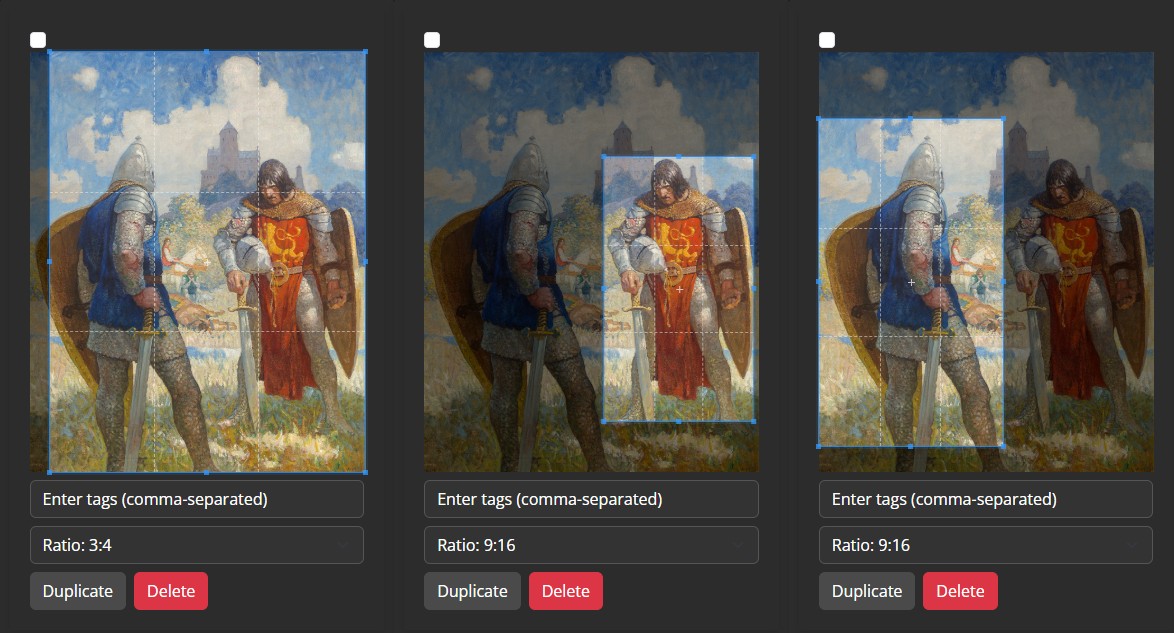
By cropping different areas or applying different aspect ratios, you can create variations that emphasize specific details. While this approach can help the model learn particular features, it’s generally better to have a large and diverse dataset of unique images for improved generalization and performance in your trained model.
Example:
N.C. Wyeth King Arthu Lora Model
I use N.C Wyeth's painting for this Lora training example. This is a lora model train on Pony, with unique 12 images, and 32 total training images after cropping.
V1 Data set:
































V1 Result:



Generated in Pony
Image 1 prompt: a knight holding a shield facing a red sky with a black sun, helmet, holding, sword, shiled, weapon, holding weapon, red sky, black sun, painting, traditional media, high contrast, best quality
Image 2 prompt: 1boy, masterpiece, best quality, good quality, knight, newest, highres, absurdres, holding, weapon, boots, sword, white dress, red armor, helmet, gauntlets, shield, sun, blue sky, full armor
Image 3 prompt: a knight holding a shield in dark green fancy armor, black sky, high quality, fantasy, dramatic lighting, high res, darkness, horse, armor
N.C. Wyeth King Arthu V1 Lora/Data Download Link:
Lora and Training Data Download link
V1 Training Afterthoughts:
The limited dataset seems to perform remarkably well in capturing N.C. Wyeth's style, even within a model like Pony. Adding more images could enhance flexibility, but with just 12 images, I think the results are incredible.
version v0.04